
Picking up where we left off…
As noted last week, I participated in an LSEG panel on the complex intersection between artificial intelligence (AI), geopolitics and investment management. Last week I wrote about how AI and geopolitics are complexly co-determined by a quest for ultimate power. As promised, this week I’m writing about how AI, and particularly large language models (LLMs), affect investment management. The answer, paradoxically, relates to the ultimate questions on life, the universe and everything, and ends up being a natural advertisement for my research.
The Ultimate Question of Life, the Universe and Everything
Readers of Douglas Adams’ The Hitchhiker’s Guide to the Galaxy “trilogy” will surely have recognized the references above, but for others let me explain. In Adams’ book, a race of hyper-intelligent, pan-dimensional mice create a supercomputer to find “the Answer to the Ultimate Question of Life, the Universe, and Everything.” After 7.5 million years the computer, “Deep Thought,” spits out the answer: “42.” The mice, puzzled and exasperated, then ask Deep Thought, “what is the Ultimate question?” Although Deep Thought cannot tell them, it designs an organic computer – the earth – that can (though it is sadly destroyed seconds before revealing the Ultimate question).
“It is better to know some of the questions than all of the answers.”
– James Thurber (American humorist)
The question matters
Adams’ amusing plot line amusingly illustrates James Thurber’s point above. An answer’s meaning may change depending on the question being asked. For instance, “Peanuts” has very different implications in response to the questions “What are your favorite nuts?” and “What are you allergic to?” Similarly, slight differences in a question can create radically different answers. E.g. “What is the meaning of life?” versus “What is the meaning of mylife?” Or, “Is it legal?” versus “Is it just?”
Answer first, as questions later
This is a serious problem for AI users: AI will provide an answer, it may even provide a good answer, but the answer it yields is only useful if you asked it the right question. If you ask your favorite LLM “What should I wear to dinner tonight?” and it suggests “smart casual trousers with a polo shirt,” you have no one to blame but yourself for your embarrassment if you fail to add the critical detail “at Buckingham Palace.” AI’s “question problem” can be acutely dangerous in investment management, especially when widely available to investors. To understand why, it is helpful to understand the effects of the quantitative revolution that has taken place in finance over the last few decades and how AI, particularly LLMs, extend them.
From Liar’s Poker to Flashboys
Finance generates immense amounts of numeric data – prices, volumes, et cetera – but until computing and digitization allowed for its rapid analysis, statistical methods were of limited use in trading. As desktop computing spread in the 1980s and began to uncover “hidden” profitable relationships in these data, banks and asset managers started to replace the quick-calculating but relatively uneducated “city boys” from Brooklyn and Bow that Michael Lewis famously caricatured in Liar’s Poker with PhDs in Mathematics, Statistics, Economics, and Physics. Even fundamental investors became “quantimental,” i.e. their subjective views are increasingly based in statistical analyses. But the “alpha” (α) – excess returns – these methods produced proved elusive. Academia churned out hordes of new quantitative PhDs to exploit every conceivable source of digital alpha across markets. Like the last mastodons, they hunted it to the furthest reaches of digitization such that three decades later Mr. Lewis wrote Flash Boys about ultra-high-frequency traders slaying alpha hiding in the nano seconds between others’ trades.
LLMs’ terra nova
AI encompasses a broad array of models that include some of the models in the “digital” revolution described above, including high-frequency algorithms. But LLMs and their early predecessors, natural language processing, opened a “land bridge” to an immense terra nova full of new alpha-dons to be hunted both by quants and their quantimental cousins. As vast as the numeric data in finance are, they represent a small fraction of the information LLMs can exploit in “unstructured” written, spoken and visual data. Previously, a corporate earnings call would yield just dozens of numbers – revenue, costs, earnings, et cetera – but now the entire call can be digitized for sentiment, nuance, hints about future sales, industry trends, et cetera. In a matter of hours, a single analyst using an LLM can scour the earnings calls of every Russell 3000 company for trends in consumer spending, margins, or passthrough of tariffs.
The herd chasing herd
The vast new information landscape opened by LLMs, in theory, offer infinite new herds of alpha. But only if you know where to look! That brings us back to the problem of Douglas Adams’ mice: what is the question?! Or, in this case questions? The very vastness of the potential space and the limits of (most) human imagination encourages the hunters themselves to herd, chasing the plentiful alpha-dons across plains of the visible horizon rather than into dark forests or up craggy mountain valleys. But LLMs make the problem of crowding potentially worse both by greatly expanding the number of hunters, and through reinforcement of biases and errors.
New hunters join the chase
In the age of computer-distilled digital data, the number of hunters were at least constrained by the throughput of mathematically oriented new graduates. But LLMs allow every Art History major (like Michael Lewis) to code in Python and query SEC databases just as did the quants of old, but now with access to far more data than before. Now everyone can be a quantimentalist alpha hunter! This is a blessing, as I describe below, but it does increase the crowds of alpha hunters.
All models have problems
But perhaps a greater problem with AI – that likely amplifies the harms caused by crowding – is error reinforcement. All optimization models are subject to error for at least four reasons: (1) misspecification, i.e. the hypothesized model may be wrong; (2) bias in the data collection – or, especially in the case of AI, data creation – that biases the result; (3) natural randomness in the data that distort results; or (4) infrequent outlier events that may be either over or underrepresented in the data, overstating (understating) the model’s fit, and understating (overstating) its risk. AI, and particularly LLMs, may be especially subject to these risks in non-obvious ways.
To error is human, AI perfects
This creates potentially serious reinforcement biases. LLMs draw their data not from the “truth” but from the available pool of human knowledge. If human understanding is wrong – or even just the understanding of a consensus of humans – the pool of knowledge will be biased and LLMs will reflect that bias. But LLM users are not independent to this process: as generators of the biased data, they are themselves biased and thus predisposed to ask questions that align with their bias. As any pollster knows, both the questions one asks and their wording greatly affect the answer returned.11 Hence, where human bias exists, the questions LLM users ask are likely to reflect “misspecification” that amplifies LLMs inherent bias (model errors (1) and (2)).
Self-reinforcing feedback loops
Consider the following feedback loop: academic economists came up with models to rationalize the low growth and inflation of the last decade; central bankers internalized those models in their speeches; Wall Street analysts mimicked them, and the press regurgitated their implications. Along came Covid and in its wake inflation, growth, interest rates, and earnings, all greatly exceeded expectations. The same academics, central bankers, analysts, and press have subsequently refined a long chain of post hoc rationalizations that either were known when the forecasts were made (e.g. fiscal policy) or were originally cited as reasons why the jump in all these variables would be “transitory” (e.g. supply constraints and demand shocks). Ask your favorite LLM why growth, inflation, interest rates, and earnings all persistently exceeded expectations in 2021-’25; does its answer reflect the “truth” or a biased pool of knowledge?
No one saw that coming
More so than traditional, structured-data models, reliance on LLMs is also likely to miss outliers and encourage herding. While both Classical and Bayesian statistics offer probabilistic measures of model fit, LLMs typically are evaluated versus pre-determined benchmarks for accuracy where the objective “truth” against which they are judged can be ambiguous (e.g. what is the correct answer to “What is the meaning of life?”). This makes the questions asked even more important. LLM optimization will “regress to the mean,” i.e. give you the most commonly accepted answers, without regard to the magnitude of variation in the actual data (model error (3)). That may be fine for “What’s the average elevation of Kansas?”; but not for “What’s the average elevation of Colorado?” It becomes especially troublesome when large outliers are possible but not prevalent in the data, e.g. “What’s the probability that Donald Trump wins the US presidency?” asked in 2016; or overrepresented in the data, e.g. “What’s the probability that Marine Le Pen wins the French presidency?” asked in 2016 (model error (4)).
Falling alpha and rising sigmas
These characteristics of AI and LLMs make their increasing use in investment management a cause of some concern. Despite the immense potential for alpha that LLMs offer, human tendencies combined with these model’s question dependency suggest they are likely to increase herding behavior in markets. Indeed, there is evidence that even in our short history with them, LLMs are impairing people’s ability to ask the right questions!22 There are two unfortunate consequences of this. The first is that just as the original digital revolution in quantitative finance bid away reliable alpha from markets, LLMs are likely to do the same, especially in areas of finance that were previously dominated by fundamental analysis (by humans) of nonstructured data. But the flip side is that herding generates significant potential for volatility, especially when the crowd is wrong. Thus, the likelihood of “six sigma” risk events is increasing, even as alpha falls.33
Something wicked this way comes
These problems are likely to be intensified by the change in the global risk environment. Technological change and – especially – political and geopolitical realignment are creating far greater Uncertainty, i.e. nonquantifiable risks. Since these risks are non-quantifiable, they are not well suited to traditional statistical analysis, and since they are infrequent or even absent from the historical record, they are less likely to be identified by LLMs.
The good news about AI
Yet, there are good reasons to cheer AI’s development and be hopeful about the opportunities it opens in investment management. For most of my career in finance the industry has consolidated as digitization created economies of scale and encouraged asset accumulation by large firms that could afford either to develop increasingly complex quantitative models or large teams of fundamental analysts (or both). As alluded above, AI levels the field immensely. Now small teams and even individual investors (or Substackers) can feasibly analyze thousands of companies with sophisticated AI-enabled screening algorithms cheaply and quickly like this one from YWR. Further, these new “hunters” are more likely to generate questions that allow them to explore the forests and hidden valleys of the pool of human knowledge.
Give alpha a chance
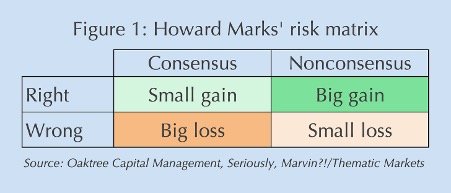
Indeed, LLMs with the right questions give individual investors a great advantage over large investors, who by definition inhabit the consensus. Using Howard Marks’ 2×2 risk framework (Figure 1), the ideal place for an investor to be is out of consensus.44 If you’re wrong, there’s little downside because there’s no crowd trying to get out with you. If you’re right, the upside can be immense as the crowd runs to join you. Being in consensus gives the exact opposite payoff profile: little upside with big risks.
The truth is out there
But being both right and out of consensus requires asking the right questions. One of the econometricians that taught me, the late Nobel laureate Clive Granger, was fond of saying “if your model doesn’t forecast, it’s misspecified; if it does, it might be correct.” My “model,” which is largely based on asking the right questions, correctly forecast Donald Trump’s election (and Brexit) in 2016, Marine Le Pen’s loss a few months later, the “Missingflation” and low interest rates of the 2010s, and high post-Covid inflation, growth, earnings, and interest rates. More importantly, because I asked the right questions initially, the reasoning behind my forecasts didn’t pivot ex post like so many who got all or most of those wrong. That’s one of the main reasons why I never worry about AI taking my job (even if I do worry that Skynet – i.e. AGI – ends humanity). It’s also a good reason why – sorry for the shameless plug – you should subscribe to Seriously, Marvin?! and Thematic Markets.











Comments are available to paid subscribers only.